Public once, public always? Privacy, egosurfing, and the availability heuristic
The Library of Congress has announced that it will be archiving all Twitter posts (tweets). You can find positive reaction on Twitter. But some have also wondered about privacy concerns. Fred Stutzman, for example, points out how even assuming that only unprotected accounts are being archived this can still be problematic.1 While some people have Twitter usernames that easily identify their owners and many allow themselves to be found based on an email address that is publicly associated with their identity, there are also many that do not. If at a future time, this account becomes associated with their identity for a larger audience than they desire, they can make their whole account viewable only by approved followers2, delete the account, or delete some of the tweets. Of course, this information may remain elsewhere on the Internet for a short or long time. But in contrast, the Library of Congress archive will be much more enduring and likely outside of individual users’ control.3 While I think it is worth examining the strategies that people adopt to cope with inflexible or difficult to use privacy controls in software, I don’t intend to do that here.
Instead, I want to relate this discussion to my continued interest in how activity streams and other information consumption interfaces affect their users’ beliefs and behaviors through the availability heuristic. In response to some comments on his first post, Stutzman argues that people overestimate the degree to which content once public on the Internet is public forever:
So why is it that we all assume that the content we share publicly will be around forever? I think this is a classic case of selection on the dependent variable. When we Google ourselves, we are confronted with what’s there as opposed to what’s not there. The stuff that goes away gets forgotten, and we concentrate on things that we see or remember (like a persistent page about us that we don’t like). In reality, our online identities decay, decay being a stochastic process. The internet is actually quite bad at remembering.
This unconsidered “selection on the dependent variable” is one way of thinking about some cases of how the availability heuristic (and use of ease-of-retrievel information more generally). But I actually think the latter is more general and more useful for describing the psychological processes involved. For example, it highlights both that there are many occurrences or interventions can can influence which cases are available to mind and that even if people have thought about cases where their content disappeared at some point, this may not be easily retrieved when making particular privacy decisions or offering opinions on others’ actions.
Stutzman’s example is but one way that the combination of the availability heuristic and existing Internet services combine to affect privacy decisions. For example, consider how activity streams like Facebook News Feed influence how people perceive their audience. News Feed shows items drawn from an individual’s friends’ activities, and they often have some reciprocal access. However, the items in the activity stream are likely unrepresentative of this potential and likely audience. “Lurkers” — people who consume but do not produce — are not as available to mind, and prolific producers are too available to mind for how often they are in the actual audience for some new shared content. This can, for example, lead to making self-disclosures that are not appropriate for the actual audience.
- This might not be the case, see Michael Zimmer and this New York Times article. [↩]
- Why don’t people do this in the first place? Many may not be aware of the feature, but even if they are, there are reasons not to use it. For example, it makes any participation in topical conversations (e.g., around a hashtag) difficult or impossible. [↩]
- Or at least this control would have to be via Twitter, likely before archiving: “We asked them [Twitter] to deal with the users; the library doesn’t want to mediate that.” [↩]
Not just predicting the present, but the future: Twitter and upcoming movies
Search queries have been used recently to “predict the present“, as Hal Varian has called it. Now some initial use of Twitter chatter to predict the future:
The chatter in Twitter can accurately predict the box-office revenues of upcoming movies weeks before they are released. In fact, Tweets can predict the performance of films better than market-based predictions, such as Hollywood Stock Exchange, which have been the best predictors to date. (Kevin Kelley)
Here is the paper by Asur and Huberman from HP Labs. Also see a similar use of online discussion forums.
But the obvious question from my previous post is, how much improvement do you get by adding more inputs to the model? That is, how does the combined Hollywood Stock Exchange and Twitter chatter model perform? The authors report adding the number of theaters the movie opens in to both models, but not combining them directly.
Search terms and the flu: preferring complex models
Simplicity has its draws. A simple model of some phenomena can be quick to understand and test. But with the resources we have today for theory building and prediction, it is worth recognizing that many phenomena of interest (e.g., in social sciences, epidemiology) are very, very complex. Using a more complex model can help. It’s great to try many simple models along the way — as scaffolding — but if you have a large enough N in an observational study, a larger model will likely be an improvement.
One obvious way a model gets more complex is by adding predictors. There has recently been a good deal of attention on using the frequency of search terms to predict important goings-on — like flu trends. Sharad Goel et al. (blog post, paper) temper the excitement a bit by demonstrating that simple models using other, existing public data sets outperform the search data. In some cases (music popularity, in particular), adding the search data to the model improves predictions: the more complex combined model can “explain” some of the variance not handled by the more basic non-search-data models.

This echos one big takeaway from the Netflix Prize competition: committees win. The top competitors were all large teams formed from smaller teams and their models were tuned combinations of several models. That is, the strategy is, take a bunch of complex models and combine them.
One way of doing this is just taking a weighted average of the predictions of several simpler models. This works quite well when your measure of the value of your model is root mean squared error (RMSE), since RMSE is convex.
While often the larger model “explains” more of the variance, what “explains” means here is just that the R-squared is larger: less of the variance is error. More complex models can be difficult to understand, just like the phenomena they model. We will continue to need better tools to understand, visualize, and evaluate our models as their complexity increases. I think the committee metaphor will be an interesting and practical one to apply in the many cases where the best we can do is use a weighted average of several simpler, pretty good models.
Apple’s “trademarked” chat bubbles: source equivocality in mobile apps and services
TechCrunch and others have been joking about Apple’s rejection of an app because it uses shiny chat bubbles, which the Apple representative claimed were trademarked:
Chess Wars was being rejected after the six week wait [because] the bubbles in its chat rooms are too shiny, and Apple has trademarked that bubbly design. […] The representative said Stump needed to make the bubbles “less shiny” and also helpfully suggested that he make the bubbles square, just to be sure.
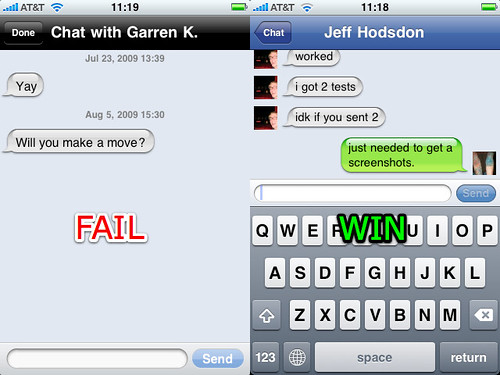
One thing that is quite striking in this situation is that it is at odds with Apple’s long history of strongly encouraging third-party developers to follow many UI guidelines — guidelines that when followed make third-party apps blend in like they’re native.1
It’s important to not read too much into this (especially since we don’t know what Apple’s more considered policy on this will end up being), but it is interesting to think about how responsibility gets spread around among mobile applications, services, and devices — and how this may be different than existing models on the desktop.My sense is that experienced desktop computer users understand at least the most important ways sources of their good and bad experiences are distinguished. For example, “locomotion” is a central metaphor in using the Web, as opposed to the conversation and manipulation metaphors of the command line / natural language interfaces and WIMP: we “go to” a site (see this interview with Terry Winograd, full .mov here). The locomotion metaphor helps people distinguish what my computer is contributing and what some distant, third-party “site” is contributing.
This is complex even on the Web, but many of these genre rules are currently being all mixed up. Google has Gmail running in your browser but on your computer. Cameraphones are recognizing objects you point them at — some by analyzing the image on the device and some by sending the device to a server to be analyzed.
This issue is sometimes identified by academics as one of source orientation and source equivocality. Though there has been some great research in this area, there is a lot we don’t know and the field is in flux: people’s beliefs about systems are changing and the important technologies and genres are still emerging.
If there’s one important place to start thinking about the craziness of the current situation of ubiquitous source equivocality is “Personalization of mass media and the growth of pseudo-community” (1987) by James Beniger that predates much of the tech at issue.
- I was led to think this by a commenter on TechCrunch, Dan Grossman, pointing out this long history. [↩]
Multitasking among tasks that share a goal: action identification theory
Right from the start of today’s Media Multitasking Workshop1, it’s clear that one big issue is just what people are talking about when they talk about multitasking. In this post, I want to highlight the relationship between defining different kinds of multitasking and people’s representations of the hierarchical structure of action.
It is helpful to start with a contrast between two kinds of cases.
Distributing attention towards a single goal
In the first, there is a single task or goal that involves dividing one’s attention, with the targets of attention somehow related, but of course somewhat independent. Patricia Greenfield used Pac-Man as an example: each of the ghosts must be attended to (in addition to Pac-Man himself), and each is moving independently, but each is related to the same larger goal.
Distributing attention among different goals
In the second kind of case, there are two completely unrelated tasks that divide attention, as in playing a game (e.g., solitaire) while also attending to a speech (e.g., in person, on TV). Anthony Wagner noted that in Greenfield’s listing of the benefits and costs of media multitasking, most of the listed benefits applied to the former case, while the costs she listed applied to the later. So keeping these different senses of multitasking straight is important.
Complications
But the conclusion should not be to think that this is a clear and stable distinction that slices multitasking phenomena in just the right way. Consider one ways of putting this distinction: the primary and secondary task can either be directed at the same goal or directed at different goals (or tasks). Let’s dig into this a bit more.2
Byron Reeves pointed out that sometimes “the IMing is about the game.” So we could distinguish whether the goal of the IMing is the same as the goal of the in-game task(s). But this making this kind of distinction requires identity conditions for goals or tasks that enable this distinction. As Ulrich Mayr commented, goals can be at many different levels, so in order to use goal identity as the criterion, one has to select a level in the hierarchy of goals.
Action identities and multitasking
We can think about this hierarchy of goals as the network of identities for an action that are connected with the “by” relation: one does one thing by doing (several) other things. If these goals are the goals of the person as they represent them, then this is the established approach taken by action identification theory (Vallacher & Wegner, 1987) — and this could be valuable lens for thinking about this. Action identification theory claims that people can report an action identity for what they are doing, and that this identity is the “prepotent identity”. This prepotent identity is generally the highest level identity under which the action is maintainable. This means that the prepotent identity is at least somewhat problematic if used to make this distinction between these two types of multitasking because then the distinction would be dependent on, e.g., how automatic or functionally transparent the behaviors involved are.
For example, if I am driving a car and everything is going well, I may represent the action as “seeing my friend Dave”. I may also represent my simultaneous, coordinating phone call with Dave under this same identity. But if driving becomes more difficult, then my prepotent identity will decrease in level in order to maintain the action. Then these two tasks would not share the prepotent action identity.
Prepotent action identities (i.e. the goal of the behavior as represented by the person in the moment) do not work to make this distinction for all uses. But I think that it actually does help makes some good distinctions about the experience of multitasking, especially if we examine change in action identities over time.
To return to case of media multitasking, consider the headline ticker on 24-hour news television. The headline ticker can be more or less related to what the talking heads are going on about. This could be evaluated as a semantic, topical relationship. But considered as a relationship of goals — and thus action identities — we can see that perhaps sometimes the goals coincide even when the content is quite different. For example, my goal may simply to be “get the latest news”, and I may be able to actually maintain this action — consuming both the headline ticker and the talking heads’ statements — under this high level identity. This is an importantly different case then if I don’t actually maintain the action at the level, but instead must descend to — and switch between — two (or more) lower level identities that are associated the two streams of content.
References
Vallacher, R. R., & Wegner, D. M. (1987). What do people think they’re doing? Action identification and human behavior. Psychological Review, 94(1), 3-15.
- The full name is the “Seminar on the impacts of media multitasking on children’s learning and development”. [↩]
- As I was writing this, the topic re-emerged in the workshop discussion. I made some comments, but I think I may not have made myself clear to everyone. Hopefully this post is a bit of an improvement. [↩]