Is thinking about monetization a waste of our best minds?
I just recently watched this talk by Jack Conte, musician, video artist, and cofounder of Patreon:
Jack dives into how rapidly the Internet has disrupted the business of selling reproducible works, such as recorded music, investigative reporting, etc. And how important — and exciting — it is build new ways for the people who create these works to be able to make a living doing so. Of course, Jack has some particular ways of doing that in mind — such as subscriptions and subscription-like patronage of artists, such as via Patreon.
But this also made me think about this much-repeated1 quote from Jeff Hammerbacher (formerly of Facebook, Cloudera, and now doing bioinformatics research):
“The best minds of my generation are thinking about how to make people click ads. That sucks.”
I certainly agree that many other types of research can be very important and impactful, and often more so than working on data infrastructure, machine learning, market design, etc. for advertising. However, Jack Conte’s talk certainly helped make the case for me that monetization of “content” is something that has been disrupted already but needs some of the best minds to figure out new ways for creators of valuable works to make money.
Some of this might be coming up with new arrangements altogether. But it seems like this will continue to occur partially through advertising revenue. Jack highlights how little ad revenue he often saw — even as his videos were getting millions of views. And newspapers’ have been less able to monetize online attention through advertising than they had been able to in print.
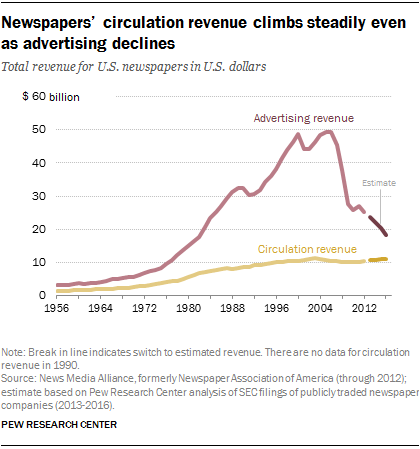
Some of this may reflect that advertising dollars were just really poorly allocated before. But improving this situation will require a mix of work on advertising — certainly beyond just getting people to click on ads — such as providing credible measurement of the effects and ROI of advertising, improving targeting of advertising, and more.
Another side of this question is that advertising remains an important part of our culture and force for attitude and behavior change. Certainly looking back on 2016 right now, many people are interested in what effects political advertising had.
So maybe it isn’t so bad if at least some of our best minds are working on online advertising.
- So often repeated that Hammerbacher said to Charlie Rose, “That’s going to be on my tombstone, I think.” [↩]
Will the desire for other perspectives trump the “friendly world syndrome”?
Some recent journalism at NPR and The New York Times has addressed some aspects of the “friendly world syndrome” created by personalized media. A theme common to both pieces is that people want to encounter different perspectives and will use available resources to do so. I’m a bit more skeptical.
If we keep seeing the same links and catchphrases ricocheting around our social networks, it might mean we are being exposed only to what we want to hear, says Damon Centola, an assistant professor of economic sociology at the Massachusetts Institute of Technology.
“You might say to yourself: ‘I am in a group where I am not getting any views other than the ones I agree with. I’m curious to know what else is out there,’” Professor Centola says.
Consider a new hashtag: diversity.
This is how Singer ends this article in which the central example is “icantdateyou” leading Egypt-related idioms as a trending topic on Twitter. The suggestion here, by Centola and Singer, is that people will notice they are getting a biased perspective of how many people agree with them and what topics people care about — and then will take action to get other perspectives.
Why am I skeptical?
First, I doubt that we really realize the extent to which media — and personalized social media in particular — bias their perception of the frequency of beliefs and events. Even though people know that fiction TV programs (e.g., cop shows) don’t aim to represent reality, heavy TV watchers (on average) substantially overestimate the percent of adult men employed in law enforcement.1 That is, the processes that produce the “friendly world syndrome” function without conscious awareness and, perhaps, even despite it. So people can’t consciously choose to seek out diverse perspectives if they don’t know they are increasingly missing them.
Second, I doubt that people actually want diversity of perspectives all that much. Even if I realize divergent views are missing from my media experience, why would I seek them out? This might be desirable for some people (but not all), and even for those, the desire to encounter people who radically disagree has its limits.
Similar ideas pop up in a NPR All Things Considered segment by Laura Sydell. This short piece (audio, transcript) is part of NPR’s “Cultural Fragmentation” series.2 The segment begins with the worry that offline bubbles are replicated online and quotes me describing how attempts to filter for personal relevance also heighten the bias towards agreement in personalized media.
But much of the piece has actually focuses on how one person — Kyra Gaunt, a professor and musician — is using Twitter to connect and converse with new and different people. Gaunt describes her experience on Twitter as featuring debate, engagement, and “learning about black people even if you’ve never seen one before”. Sydell’s commentary identifies the public nature of Twitter as an important factor in facilitating experiencing diverse perspectives:
But, even though there is a lot of conversation going on among African Americans on Twitter, Professor Gaunt says it’s very different from the closed nature of Facebook because tweets are public.
I think this is true to some degree: much of the content produced by Facebook users is indeed public, but Facebook does not make it as easily searchable or discoverable (e.g., through trending topics). But more importantly, Facebook and Twitter differ in their affordances for conversation. Facebook ties responses to the original post, which means both that the original poster controls who can reply and that everyone who replies is part of the same conversation. Twitter supports replies through the @reply mechanism, so that anyone can reply but the conversation is fragmented, as repliers and consumers often do not see all replies. So, as I’ve described, even if you follow a few people you disagree with on Twitter, you’ll most likely see replies from the other people you follow, who — more often than not — you agree with.
Gaunt’s experience with Twitter is certainly not typical. She has over 3,300 followers and follows over 2,400, so many of her posts will generate replies from people she doesn’t know well but whose replies will appear in her main feed. And — if she looks beyond her main feed to the @Mentions page — she will see the replies from even those she does not follow herself. On the other hand, her followers will likely only see her posts and replies from others they follow.3
Nonetheless, Gaunt’s case is worth considering further, as does Sydell:
SYDELL: Gaunt says she’s made new friends through Twitter.
GAUNT: I’m meeting strangers. I met with two people I had engaged with through Twitter in the past 10 days who I’d never met in real time, in what we say in IRL, in real life. And I met them, and I felt like this is my tribe.
SYDELL: And Gaunt says they weren’t black. But the key word for some observers is tribe. Although there are people like Gaunt who are using social media to reach out, some observers are concerned that she is the exception to the rule, that most of us will be content to stay within our race, class, ethnicity, family or political party.
So Professor Gaunt is likely making connections with people she would not have otherwise. But — it is at least tempting to conclude from “this is my tribe” — they are not people with radically different beliefs and values, even if they have arrived at those beliefs and values from a membership in a different race or class.
- Gerbner, G., Gross, L., Morgan, M., & Signorielli, N. (1980). The “Mainstreaming” of America: Violence Profile No. 11. Journal of Communication, 30(3), 10-29. [↩]
- I was also interviewed for the NPR segment. [↩]
- One nice feature in “new Twitter” — the recently refresh of the Twitter user interface — is that clicking on a tweet will show some of the replies to it in the right column. This may offer an easier way for followers to discover diverse replies to the people they follow. But it is also not particularly usable, as it is often difficult to even trace what a reply is a reply to. [↩]
The “friendly world syndrome” induced by simple filtering rules
I’ve written previously about how filtered activity streams [edit: i.e. news feeds] can lead to biased views of behaviors in our social neighborhoods. Recent conversations with two people writing popular-press books on related topics have helped me clarify these ideas. Here I reprise previous comments on filtered activity streams, aiming to highlight how they apply even in the case of simple and transparent personalization rules, such as those used by Twitter.
—
Birds of a feather flock together. Once flying together, a flock is also subject to the same causes (e.g., storms, pests, prey). Our friends, family, neighbors, and colleagues are more similar to us for similar reasons (and others). So we should have no illusions that the behaviors, attitudes, outcomes, and beliefs of our social neighborhood are good indicators of those of other populations — like U.S. adults, Internet users, or homo sapiens of the past, present, or future. The apocryphal Pauline Kael quote “How could Nixon win? No one I know voted for him” suggests both the ease and error of this kind of inference. I take it as a given that people’s estimates of larger populations’ behaviors and beliefs are often biased in the direction of the behaviors and beliefs in their social neighborhoods. This is the case with and without “social media” and filtered activity streams — and even mediated communication in general.
That is, even without media, our personal experiences are not “representative” of the American experience, human experience, etc., but we do (and must) rely on it anyway. One simple cognitive tool here is using “ease of retrieval” to estimate how common or likely some event is: we can estimate how common something is based on how easy it is to think of. So if something prompts someone to consider how common a type of event is, they will (on average) estimate the event as more common if it is more easy to think of an example of the event, imagine the event, etc. And our personal experiences provide these examples and determine how easy they are to bring to mind. Both prompts and immediately prior experience can thus affect these frequency judgments via ease of retrieval effects.
Now this is not to say that we should think as ease of retrieval heuristics as biases per se. Large classes and frequent occurrences are often more available to mind than those that are smaller or less frequent. It is just that this is also often not the case, especially when there is great diversity in frequency among physical and social neighborhoods. But certainly we can see some cases where these heuristics fail.
Media are powerful sources of experiences that can make availability and actual frequency diverge, whether by increasing the biases in the direction of projecting our social neighborhoods onto larger population or in other, perhaps unexpected directions. In a classic and controversial line of research in the 1970s and 80s, Gerbner and colleagues argued that increased television-watching produces a “mean world syndrome” such that watching more TV causes people to increasingly overestimate, e.g., the fraction of adult U.S. men employed in law enforcement and the probability of being a victim of violent crime. Their work did not focus on investigating heuristics producing these effects, but others have suggested the availability heuristic (and related ease of retrieval effects) as at work. So even if my social neighborhood has fewer cops or victims of violent crime than the national average, media consumption and the availability heuristic can lead me to overestimate both.
Personalized and filtered activity streams certainly also affect us through some of the same psychological processes, leading to biases in users’ estimates of population-wide frequencies. They can aIso bias inference about our own social neighborhoods. If I try to estimate how likely a Facebook status update by a friend is to receive a comment, this estimate will be affected by the status updates I have seen recently. And if content with comments is more likely to be shown to me in my personalized filtered activity stream (a simple rule for selecting more interesting content, when there is too much for me to consume it all), then it will be easier for me to think of cases in which status updates by my friends do receive comments.
In my previous posts on these ideas, I have mainly focused on effects on beliefs about my social neighborhood and specifically behaviors and outcomes specific to the service providing the activity stream (e.g., receiving comments). But similar effects apply for beliefs about other behaviors, opinions, and outcomes. In particular, filtered activity streams can increase the sense that my social neighborhood (and perhaps the world) agrees with me. Say that content produced by my Facebook friends with comments and interaction from mutual friends is more likely to be shown in my filtered activity streams. Also assume that people are more likely to express their agreement in such a way than substantial disagreement. As long as I am likely to agree with most of my friends, then this simple rule for filtering produces an activity stream with content I agree with more than an unfiltered stream would. Thus, even if I have a substantial minority of friends with whom I disagree on politics, this filtering rule would likely make me see less of their content, since it is less likely to receive (approving) comments from mutual friends.
I’ve been casually calling this larger family of effects this the “friendly world syndrome” induced by filtered activity streams. Like the mean world syndrome of the television cultivation research described above, this picks out a family of unintentional effects of media. Unlike the mean world syndrome, the friendly world syndrome includes such results as overestimating how many friends I have in common with my friends, how much positive and accomplishment-reporting content my friends produce, and (as described) how much I agree with my friends.1
Even though the filtering rules I’ve described so far are quite simple and appealing, they still are more consistent with versions of activity streams that are filtered by fancy relevance models, which are often quite opaque to users. Facebook News Feed — and “Top News” in particular — is the standard example here. On the other hand, one might think that these arguments do not apply to Twitter, which does not apply any kind of machine learning model estimating relevance to filtering users’ streams. But Twitter actually does implement a filtering rule with important similarities to the “comments from mutual friends” rule described above. Twitter only shows “@replies” to a user on their home page when that user is following both the poster of the reply and the person being replied to.2 This rule makes a lot of sense, as a reply is often quite difficult to understand without the original tweet. Thus, I am much more likely to see people I follow replying to people I follow than to others (since the latter replies are encountered only from browsing away from the home page. I think this illustrates how even a straightforward, transparent rule for filtering content can magnify false consensus effects.
One aim in writing this is to clarify that a move from filtering activity streams using opaque machine learning models of relevance to filtering them with simple, transparent, user-configurable rules will likely be insufficient to prevent the friendly world syndrome. This change might have many positive effects and even reduce some of these effects by making people mindful of the filtering.3 But I don’t think these effects are so easily avoided in any media environment that includes sensible personalization for increased relevance and engagement.
- This might suggest that some of the false consensus effects observed in recent work using data collected about Facebook friends could be endogenous to Facebook. See Goel, S., Mason, W., & Watts, D. J. (2010). Real and perceived attitude agreement in social networks. Journal of Personality and Social Psychology, 99(4), 611-621. doi:10.1037/a0020697 [↩]
- Twitter offers the option to see all @replies written by people one is following, but 98% of users use the default option. Some users were unhappy with an earlier temporary removal of this feature. My sense is that the biggest complaint was that removing this feature removed a valuable means for discovering new people to follow. [↩]
- We are investigating this in ongoing experimental research. Also see Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality and Social Psychology, 61(2), 195-202. doi:10.1037/0022-3514.61.2.195 [↩]
Public once, public always? Privacy, egosurfing, and the availability heuristic
The Library of Congress has announced that it will be archiving all Twitter posts (tweets). You can find positive reaction on Twitter. But some have also wondered about privacy concerns. Fred Stutzman, for example, points out how even assuming that only unprotected accounts are being archived this can still be problematic.1 While some people have Twitter usernames that easily identify their owners and many allow themselves to be found based on an email address that is publicly associated with their identity, there are also many that do not. If at a future time, this account becomes associated with their identity for a larger audience than they desire, they can make their whole account viewable only by approved followers2, delete the account, or delete some of the tweets. Of course, this information may remain elsewhere on the Internet for a short or long time. But in contrast, the Library of Congress archive will be much more enduring and likely outside of individual users’ control.3 While I think it is worth examining the strategies that people adopt to cope with inflexible or difficult to use privacy controls in software, I don’t intend to do that here.
Instead, I want to relate this discussion to my continued interest in how activity streams and other information consumption interfaces affect their users’ beliefs and behaviors through the availability heuristic. In response to some comments on his first post, Stutzman argues that people overestimate the degree to which content once public on the Internet is public forever:
So why is it that we all assume that the content we share publicly will be around forever? I think this is a classic case of selection on the dependent variable. When we Google ourselves, we are confronted with what’s there as opposed to what’s not there. The stuff that goes away gets forgotten, and we concentrate on things that we see or remember (like a persistent page about us that we don’t like). In reality, our online identities decay, decay being a stochastic process. The internet is actually quite bad at remembering.
This unconsidered “selection on the dependent variable” is one way of thinking about some cases of how the availability heuristic (and use of ease-of-retrievel information more generally). But I actually think the latter is more general and more useful for describing the psychological processes involved. For example, it highlights both that there are many occurrences or interventions can can influence which cases are available to mind and that even if people have thought about cases where their content disappeared at some point, this may not be easily retrieved when making particular privacy decisions or offering opinions on others’ actions.
Stutzman’s example is but one way that the combination of the availability heuristic and existing Internet services combine to affect privacy decisions. For example, consider how activity streams like Facebook News Feed influence how people perceive their audience. News Feed shows items drawn from an individual’s friends’ activities, and they often have some reciprocal access. However, the items in the activity stream are likely unrepresentative of this potential and likely audience. “Lurkers” — people who consume but do not produce — are not as available to mind, and prolific producers are too available to mind for how often they are in the actual audience for some new shared content. This can, for example, lead to making self-disclosures that are not appropriate for the actual audience.
- This might not be the case, see Michael Zimmer and this New York Times article. [↩]
- Why don’t people do this in the first place? Many may not be aware of the feature, but even if they are, there are reasons not to use it. For example, it makes any participation in topical conversations (e.g., around a hashtag) difficult or impossible. [↩]
- Or at least this control would have to be via Twitter, likely before archiving: “We asked them [Twitter] to deal with the users; the library doesn’t want to mediate that.” [↩]
Using social networks for persuasion profiling
BusinessWeek has an exhuberant review of current industry research and product development related to understanding social networks using data from social network sites and other online communication such as email. It includes snippets from people doing very interesting social science research, like Duncan Watts, Cameron Marlow, and danah boyd. So it is worth checking out, even if you’re already familiar with the Facebook Data Team’s recent public reports (“Maintained Relationships”, “Gesundheit!”).
But I actually want to comment not on their comments, but on this section:
In an industry where the majority of ads go unclicked, even a small boost can make a big difference. One San Francisco advertising company, Rapleaf, carried out a friend-based campaign for a credit-card company that wanted to sell bank products to existing customers. Tailoring offers based on friends’ responses helped lift the average click rate from 0.9% to 2.7%. Although 97.3% of the people surfed past the ads, the click rate still tripled.
Rapleaf, which has harvested data from blogs, online forums, and social networks, says it follows the network behavior of 480 million people. It furnishes friendship data to help customers fine-tune their promotions. Its studies indicate borrowers are a better bet if their friends have higher credit ratings. This might mean a home buyer with a middling credit risk score of 550 should be treated as closer to 600 if most of his or her friends are in that range, says Rapleaf CEO Auren Hoffman.
The idea is that since you are more likely to behave like your friends, their behavior can be used to profile you and tailor some marketing to be more likely to result in compliance.
In the Persuasive Technology Lab at Stanford University, BJ Fogg has long emphasized how powerful and worrying personalization based on this kind of “persuasion profile” can be. Imagine that rather than just personalizing screens based on the books you are expected to like (a familiar idea), Amazon selects the kinds of influence strategies used based on a representation of what strategies work best against you: “Dean is a sucker for limited-time offers”, “Foot-in-the-door works really well against Domenico, especially when he is buying a gift.”
In 2006 two of our students, Fred Leach and Schuyler Kaye, created this goofy video illustrating approximately this concept:
My sense is that this kind of personalization is in wide use at places like Amazon, except that their “units of analysis/personalization” are individual tactics (e.g., Gold Box offers), rather than the social influence strategies that can be implemented in many ways and in combination with each other.
What’s interesting about the Rapleaf work described by BusinessWeek is that this enables persuasion profiling even before a service provider or marketer knows anything about you — except that you were referred by or are otherwise connected to a person. This gives them the ability to estimate your persuasion profile by using your social neighborhood, even if you haven’t disclosed this information about your social network.
While there has been some research on individual differences in responses to influence strategies (including when used by computers), as far as I know there isn’t much work on just how much the responses of friends covary. As a tool for influencers online, it doesn’t matter as much whether this variation explained by friends’ responses is also explained by other variables, as long as those variables aren’t available for the influencers to collect. But for us social scientists, it would be interesting to understand the mechanism by which there is this relationship: is it just that friends are likely to be similar in a bunch of ways and these predict our “persuasion profiles”, or are the processes of relationship creation that directly involve these similarities.
This is an exciting and scary direction, and I want to learn more about it.