Aardvark’s use of Wizard of Oz prototyping to design their social interfaces
The Wall Street Journal’s Venture Capital Dispatch reports on how Aardvark, the social question asking and answering service recently acquired by Google, used a Wizard of Oz prototype to learn about how their service concept would work without building all the tech before knowing if it was any good.
Aardvark employees would get the questions from beta test users and route them to users who were online and would have the answer to the question. This was done to test out the concept before the company spent the time and money to build it, said Damon Horowitz, co-founder of Aardvark, who spoke at Startup Lessons Learned, a conference in San Francisco on Friday.
“If people like this in super crappy form, then this is worth building, because they’ll like it even more,” Horowitz said of their initial idea.
At the same time it was testing a “fake” product powered by humans, the company started building the automated product to replace humans. While it used humans “behind the curtain,” it gained the benefit of learning from all the questions, including how to route the questions and the entire process with users.
This is a really good idea, as I’ve argued before on this blog and in a chapter for developers of mobile health interventions. What better way to (a) learn about how people will use and experience your service and (b) get training data for your machine learning system than to have humans-in-the-loop run the service?
My friend Chris Streeter wondered whether this was all done by Aardvark employees or whether workers on Amazon Mechanical Turk may have also been involved, especially in identifying the expertise of the early users of the service so that the employees could route the questions to the right place. I think this highlights how different parts of a service can draw on human and non-human intelligence in a variety of ways — via a micro-labor market, using skilled employees who will gain hands-on experience with customers, etc.
I also wonder what UIs the humans-in-the-loop used to accomplish this. It’d be great to get a peak. I’d expect that these were certainly rough around the edges, as was the Aardvark customer-facing UI.
Aardvark does a good job of being a quite sociable agent (e.g., when using it via instant messaging) that also gets out of the way of the human–human interaction between question askers and answers. I wonder how the language used by humans to coordinate and hand-off questions may have played into creating a positive para-social interaction with vark.
Apple’s “trademarked” chat bubbles: source equivocality in mobile apps and services
TechCrunch and others have been joking about Apple’s rejection of an app because it uses shiny chat bubbles, which the Apple representative claimed were trademarked:
Chess Wars was being rejected after the six week wait [because] the bubbles in its chat rooms are too shiny, and Apple has trademarked that bubbly design. […] The representative said Stump needed to make the bubbles “less shiny” and also helpfully suggested that he make the bubbles square, just to be sure.
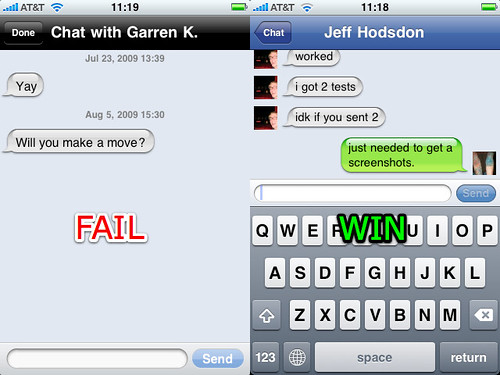
One thing that is quite striking in this situation is that it is at odds with Apple’s long history of strongly encouraging third-party developers to follow many UI guidelines — guidelines that when followed make third-party apps blend in like they’re native.1
It’s important to not read too much into this (especially since we don’t know what Apple’s more considered policy on this will end up being), but it is interesting to think about how responsibility gets spread around among mobile applications, services, and devices — and how this may be different than existing models on the desktop.My sense is that experienced desktop computer users understand at least the most important ways sources of their good and bad experiences are distinguished. For example, “locomotion” is a central metaphor in using the Web, as opposed to the conversation and manipulation metaphors of the command line / natural language interfaces and WIMP: we “go to” a site (see this interview with Terry Winograd, full .mov here). The locomotion metaphor helps people distinguish what my computer is contributing and what some distant, third-party “site” is contributing.
This is complex even on the Web, but many of these genre rules are currently being all mixed up. Google has Gmail running in your browser but on your computer. Cameraphones are recognizing objects you point them at — some by analyzing the image on the device and some by sending the device to a server to be analyzed.
This issue is sometimes identified by academics as one of source orientation and source equivocality. Though there has been some great research in this area, there is a lot we don’t know and the field is in flux: people’s beliefs about systems are changing and the important technologies and genres are still emerging.
If there’s one important place to start thinking about the craziness of the current situation of ubiquitous source equivocality is “Personalization of mass media and the growth of pseudo-community” (1987) by James Beniger that predates much of the tech at issue.
- I was led to think this by a commenter on TechCrunch, Dan Grossman, pointing out this long history. [↩]
Being a lobster and using a hammer: “homuncular flexibility” and distal attribution
Jaron Lanier (2006) calls the ability of humans to learn to control virtual bodies that are quite different than our own “homuncular flexibility”. This is, for him, a dangerous idea. The idea is that the familiar mapping of the body represented in the cortical homunculus is only one option – we can flexibly act (and perceive) using quite other mappings, e.g., to virtual bodies. Your body can be tracked, and these movements can be used to control a lobster in virtual reality – just as one experiences (via head-mounted display, haptic feedback, etc.) the virtual space from the perspective of the lobster under your control.
This name and description makes this sound quite like science fiction. In this post, I assimilate homuncular flexibility to the much more general phenomenon of distal attribution (Loomis, 1992; White, 1970). When I have a perceptual experience, I can just as well attribute that experience – and take it as being directed at or about – more proximal or distal phenomena. For example, I can attribute it to my sensory surface, or I can attribute it to a flower in the distance. White (1970) proposed that more distal attribution occurs when the afference (perception) is lawfully related to efference (action) on the proximal side of that distal entity. That is, if my action and perception are lawfully related on “my side” of that entity in the causal tree, then I will make attributions to that entity. Loomis (1992) adds the requirement that this lawful relationship be successfully modeled. This is close, but not quite right, for if I can make distal attributions even in the absence of an actual lawful relationship that I successfully model, my (perhaps inaccurate) modeling of a (perhaps non-existent) lawful relationship will do just fine.
Just as I attribute a sensory experience to a flower and not the air between me and the flower, so the blind man or the skilled hammer-user can attribute a sensory experience to the ground or the nail, rather than the handle of the cane or hammer. On consideration, I think we can see that these phenomena are very much what Lanier is talking about. When I learn to operate (and, not treated by Lanier, 2006, sense) my lobster-body, it is because I have modeled an efference–afference relationship, yielding a kind of transparency. This is a quite familiar sort of experience. It might still be a quite dangerous or exciting idea, but its examples are ubiquitous, not restricted to virtual reality labs.
Lanier paraphrases biologist Jim Boyer as counting this capability as a kind of evolutionary artifact – a spandrel in the jargon of evolutionary theory. But I think a much better just-so evolutionary story can be given: it is this capability – to make distal attributions to the limits of the efference–afference relationships we successfully model – that makes us able to use tools so effectively. At an even more basic and general level, it is this capability that makes it possible for us to communicate meaningfully: our utterances have their meaning in the context of triangulating with other people such that the content of what we are saying is related to the common cause of both of our perceptual experiences (Davidson, 1984).
References
Davidson, D. (1984). Inquiries into Truth and Interpretation. Oxford: Clarendon Press.
Lanier, J. (2006). Homuncular flexibility. Edge.
Loomis, J. M. (1992). Distal attribution and presence. Presence: Teleoperators and Virtual Environments, 1(1), 113-119.
White, B. W. (1970). Perceptual findings with the vision-substitution system. IEEE Transactions on Man-Machine Systems, 11(1), 54-58.
Transformed social interaction and actively mediated communication
Transformed social interaction (TSI) is modification, filtering, and synthesis of representations of face-to-face communication behavior, identity cues, and sensing in a collaborative virtual environment (CVE): TSI flexibly and strategically decouples representation from behavior. In this post, I want to extend this notion of TSI, as presented in Bailenson et al. (2005), in two general ways. We have begun calling the larger category actively mediated communication.1
First, I want to consider a larger category of strategic mediation in which no communication behavior is changed or added between different existing participants. This includes applying influence strategies to the feedback to the communicator as in coaching (e.g., Kass 2007) and modification of the communicator’s identity as presented to himself (i.e. the transformations of the Proteus effect). This extension entails a kind of unification of TSI with persuasive technology for computer-mediated communication (CMC; Fogg 2002, Oinas-Kukkonen & Harjumaa 2008).
Second, I want to consider a larger category of media in which the same general ideas of TSI can be manifest, albeit in quite different ways. As described by Bailenson et al. (2005), TSI is (at least in exemplars) limited to transformations of representations of the kind of non-verbal behavior, sensing, and identity cues that appear in face-to-face communication, and thus in CVEs. I consider examples from other forms of communication, including active mediation of the content, verbal or non-verbal, of a communication.
Feedback and influence strategies: TSI and persuasive technology
TSI is exemplified by direct transformation that is continuous and dynamic, rather than, e.g., static anonymization or pseudonymization. These transformations are complex means to strategic ends, and they function through a “two-step” programmatic-psychological process. For example, a non-verbal behavior is changed (modified, filtered, replaced), and then the resulting representation affects the end through a psychological process in other participants. Similar ends can be achieved by similar means in the second (psychological) step, without the same kind of direct programmatic change of the represented behavior.
In particular, consider coaching of non-verbal behavior in a CVE, a case already considered as an example of TSI (Bailenson et al. 2005, pp. 434-6), if not a particularly central one. In one case, auxiliary information is used to help someone interact more successfully:
In those interactions, we render the interactants’ names over their heads on floating billboards for the experimenter to read. In this manner the experimenter can refer to people by name more easily. There are many other ways to use these floating billboards to assist interactants, for example, reminders about the interactant’s preferences or personality (e.g., “doesn’t respond well to prolonged mutual gaze”). (Bailenson et al. 2005, pp. 435-436)
While this method can bring about change in non-verbal behaviors as represented in the CVE and thus achieve the same strategic goals by the same means in the second (psychological) step, it does not do so in the characteristic TSI way: it doesn’t decouple the representation from the behavior; instead it changes the behavior itself in the desired way. I think our understanding of the core of TSI is improved by excluding this kind of active mediation (even that presented by Bailenson et al.) and considering it instead a proper part of the superset – actively mediated communication. With this broadened scope we can take advantage of the wider range of strategies, taxonomies, and examples available from the study of persuasive technology.
TSI ideas outside CVEs
TSI is established as applying to CVEs. Standard TSI examples take place in CVEs and the feasibility of TSI is discussed with regard to CVEs. This focus is also manifest in the fact that it is behaviors, identity cues, and sensing that are normally available that are the starting point for transformation. Some of the more radical transformations of sensing and identity are nonetheless explained with reference to real-world manifestation: for example, helpers walk like ghosts amongst those you are persuading, reporting back on what they learn.
But I think this latter focus is just an artifact of the fact that, in a CVE, all the strategic transformations have to be manifest as representations of face-to-face encounters. As evidence for the anticipation of the generalization of TSI ideas beyond CVEs, we see that Bailenson et al. (2005, p. 428) introduce TSI with examples from the kind of outright blocking of any representation of particular non-verbal behaviors in telephone calls. Of course, this is not the kind of dynamic transformation characteristic of TSI, but this highlights how TSI ideas make sense outside of CVEs as well. To make it more clear what I mean by this, I present three examples: transformation of a shared drawing, coaching and augmentation in face-to-face conversation, and aggregation and synthesis in an SNS-based event application, like Facebook Events.
This more general notion of actively mediated communication is present in the literature as early as 1968 with the work of Licklider & Taylor (1968). In one interesting example, which is also a great example of 1960s gender roles, a man is draws an arrow-pierced heart with his initials and the initials of a romantic interest or partner, but when this heart is shared with her (perhaps in real time as he draws it), it is rendered as a beautiful heart with little resemblance to his original, poor sketch. The figure illustrating the example is captioned, “A communication system should make a positive contribution to the discovery and arousal of interests” (Licklider & Taylor 1968, p. 26). This example clearly exemplifies the idea of TSI – decoupling the original behavior from its representation in a strategic way that requires an intelligent process (or human-in-the-loop) making the transformation responsive to the specific circumstances and goals.
Licklider & Taylor also consider examples in which computers take an active role in a face-to-face presentation by adding a shared, persuasive simulation (cf. Fogg 2002 on computers in the functional role of interactive media such as games and simulations). But a clearer example, that also bears more resemblance to characteristic TSI examples, is conversation and interaction coaching via a wireless headset that can determine how much each participant is speaking, for how long, and how often they interrupt each other (Kass 2007). One could even imagine a case with greater similarity to the TSI example considered in the previous case: a device whispers in your ear the known preferences of the person you are talking to face-to-face (e.g., that he doesn’t respond well to prolonged mutual gaze).

Finally, I want to share an example that is a bit farther afield from TSI exemplars, but highlights how ubiquitous this general category is becoming. Facebook includes a social event planning application with which users can create and comment on events, state their plans to attend, and share personal media and information before and after it occurs. Facebook presents relevant information about one’s network in a single “News Feed”. Event related items can appear in this feed, and they feature active mediation: a user can see an item stating that “Jeff, Angela, Rich, and 6 other friends are attending X. It is at 9pm tonight” – but none of these people or the event creator, ever wrote this text. It has been generated strategically: it is encouraging considering coming to the event and it is designed to maximize the user’s sense of relevance of their News Feed. The original content, peripheral behavior, and form of their communications have been aggregated and synthesized into a new communication that better suits the situation than the original.
Source orientation in actively mediated communication
Bailenson et al. (2005) considers the consequences of TSI for trust in CVEs and how possible TSI detection is. I’ve suggested that we can see TSI-like phenomena, both actual and possible, outside of CVEs and outside of a narrow version of TSI in which directly changing (programmatically) the represented behavior without changing the actual behavior is required. Many of the same consequences for trust may apply.
But even when the active mediation is to some degree explicit – participants are aware that some active mediation is going on, though perhaps not exactly what – interesting questions about source orientation still apply. There is substantial evidence that people orient to the proximal rather than distal source in use of computers and other media (Sundar & Nass 2000, Nass & Moon 2000), but this work has been limited to relatively simple situations, rather than the complex multi-sourced, actively mediated communications under discussion. I think we should expect that proximality will not consistently predict degree of source orientation (impact of source characteristics) in these circumstances: the most proximal source may be a dumb terminal/pipe (cf. the poor evidence for proximal source orientation in the case of televisions, Reeves & Nass 1996), or the most proximal source may be an avatar, the second most proximal might be a cyranoid/ractor or a computer process, while the more distant is the person whose visual likeness is similar to that of the avatar; and in these cases one would expect the source orientation to not be the most proximal, but to be the sources that are more phenomenologically present and more available to mind.
This seems like a promising direction for research to me. Most generally, it is part of the study of source orientation in more complex configurations – with multiple devices, multiple sources, and multiple brands and identities. Consider a basic three condition experiment in which participants interact with another person and are either told (1) nothing about any active mediation, (2) there is a computer actively mediating the communications of the other person, (3) there is a human (or perhaps multiple humans) actively mediating the communications of the other person. I am not sure this is the best design, but I think it hints in the direction of the following questions:
- When and how do people apply familiar social cognition strategies (e.g., folk psychology of propositional attitudes) to understanding, explaining, and predicting the behavior of a collection of people (e.g., multiple cyranoids, or workers in a task completion market like Amazon Mechanical Turk)?
- What differences are there in social responses, source orientation, and trust between active mediation that is (ostensibly) carried out by (1) a single human, (2) multiple humans each doing very small pieces, (3) a computer?
References
Eckles, D., Ballagas, R., Takayama, L. (unpublished manuscript). The Design Space of Computer-Mediated Communication: Dimensional Analysis and Actively Mediated Communication.
Fogg, B.J. (2002). Persuasive Technology: Using Computers to Change What We Think and Do. Morgan Kaufmann.
Kass, A. (2007). Transforming the Mobile Phone into a Personal Performance Coach. Mobile Persuasion: 20 Perspectives on the Future of Influence, ed. B.J. Fogg & D. Eckles, Stanford Captology Media.
Licklider, J.C.R., & Taylor, R.W. (1968). The Computer as a Communication Device. Science and Technology, April 1968. Page numbers from version reprinted at http://gatekeeper.dec.com/pub/DEC/SRC/research-reports/abstracts/src-rr-061.html.
Nass, C., and Moon, Y. (2000). Machines and Mindlessness: Social Responses to Computers. Journal of Social Issues, 56(1), 81-103.
Oinas-Kukkonen, H., & Harjumaa, M. (2008). A Systematic Framework for Designing and Evaluating Persuasive Systems. In Proceedings of Persuasive Technology: Third International Conference, Springer, pp. 164-176.
Sundar, S. S., & Nass, C. (2000). Source Orientation in Human-Computer Interaction Programmer, Networker, or Independent Social Actor? Communication Research, 27(6).
- This idea is expanded upon in Eckles, Ballagas, and Takayama (ms.), to be presented at the workshop on Socially Mediating Technologies at CHI 2009. This working paper will be available online soon. [↩]
Source orientation and persuasion in multi-device and multi-context interactions
At the Social Media Workshop, Katarina Segerståhl presented her on-going work on what she has termed extended information services or distributed user experiences — human-computer interactions that span multiple and heterogeneous devices (Segerståhl & Oinas-Kukkonen 2007). As a central example, she studies a persuasive technology service for planning, logging, reviewing, and motivating exercise: these parts of the experience are distributed across the user’s PC, mobile phone, and heart rate monitor.
In one interesting observation, Segerståhl notes that the specific user interfaces on one device can be helpful mental images even when a different device is in use: participants reported picturing their workout plan as it appeared on their laptop and using it to guide their actions during their workout, during which the obvious, physically present interface with the service was the heart rate monitor, not the earlier planning visualization. Her second focus is how to make these user experiences coherent, with clear practical applications in usability and user experience design (e.g., how can designers make the interfaces both appropriately consistent and differentiated?).
In this post, I want to connect this very interesting and relevant work with some other research at the historical and theoretical center of persuasive technology: source orientation in human-computer interaction. First, I’ll relate source orientation to the history and intellectual context of persuasive technology. Then I’ll consider how multi-device and multi-context interactions complicate source orientation.
Source orientation, social responses, and persuasive technology
As an incoming Ph.D. student at Stanford University, B.J. Fogg already had the goal of improving generalizable knowledge about how interactive technologies can change attitudes and behaviors by design. His previous graduate studies in rhetoric and literary criticism had given him understanding of one family of academic approaches to persuasion. And in running a newspaper and consulting on many document design (Schriver 1997) projects, the challenges and opportunities of designing for persuasion were to him clearly both practical and intellectually exciting.
The ongoing research of Profs. Clifford Nass and Byron Reeves attracted Fogg to Stanford to investigate just this. Nass and Reeves were studying people’s mindless social responses to information and communication technologies. Cliff Nass’s research program — called Computers as (or are) Social Actors (CASA) — was obviously relevant: if people treat computers socially, this “opens the door for computers to apply […] social influence” to change attitudes and behaviors (Fogg 2002, p. 90). While clearly working within this program, Fogg focused on showing behavioral evidence of these responses (e.g., Fogg & Nass 1997): both because of the reliability of these measures and the standing of behavior change as a goal of practitioners.
Source orientation is central to the CASA research program — and the larger program Nass shared with Reeves. Underlying people’s mindless social responses to communication technologies is the fact that they often orient towards a proximal source rather than a distal one — even when under reflective consideration this does not make sense: people treat the box in front of them (a computer) as the source of information, rather than a (spatially and temporally) distant programmer or content creator. That is, their source orientation may not match the most relevant common cause of the the information. This means that features of the proximal source unduly influence e.g. the credibility of information presented or the effectiveness of attempts at behavior change.
For example, people will reciprocate with a particular computer if it is helpful, but not the same model running the same program right next to it (Fogg & Nass 1997, Moon 2000). Rather than orienting to the more distal program (or programmer), they orient to the box.1
Multiple devices, Internet services, and unstable context
These source orientation effects have been repeatedly demonstrated by controlled laboratory experiments (for reviews, see Nass & Moon 2000, Sundar & Nass 2000), but this research has largely focused on interactions that do not involve multiple devices, Internet services, or use in changing contexts. How is source orientation different in human-computer interactions that have these features?
This question is of increasing practical importance because these interactions now make up a large part of our interactions with computers. If we want to describe, predict, and design for how people use computers everyday — checking their Facebook feed on their laptop and mobile phone, installing Google Desktop Search and dialing into Google 411, or taking photos with their Nokia phone and uploading them to Nokia’s Ovi Share — then we should test, extend, and/or modify our understanding of source orientation. So this topic matters for major corporations and their closely guarded brands.
So why should we expect that multiple devices, Internet services, and changing contexts of use will matter so much for source orientation? After having explained the theory and evidence above, this may already be somewhat clear, so I offer some suggestive questions.
- If much of the experience (e.g. brand, visual style, on-screen agent) is consistent across these changes, how much will the effects of characteristics of the proximal source — the devices and contexts — be reduced?
- What happens when the proximal device could be mindfully treated as a source (e.g., it makes its own contribution to the interaction), but so does a distance source (e.g., a server)? This could be especially interesting with different branding combination between the two (e.g., the device and service are both from Apple, or the device is from HTC and service is from Google).
- What if the visual style or manifestation of the distal source varies substantially with the device used, perhaps taking on a style consistent with the device? This can already happen with SMS-based services, mobile Java applications, and voice agents that help you access distant media and services.
References
- This actually is subject to a good deal of cross-cultural variation. Similar experiments with Japanese — rather than American — participants show reciprocity to groups of computers, rather than just individuals (Katagiri et al.) [↩]