Public once, public always? Privacy, egosurfing, and the availability heuristic
The Library of Congress has announced that it will be archiving all Twitter posts (tweets). You can find positive reaction on Twitter. But some have also wondered about privacy concerns. Fred Stutzman, for example, points out how even assuming that only unprotected accounts are being archived this can still be problematic.1 While some people have Twitter usernames that easily identify their owners and many allow themselves to be found based on an email address that is publicly associated with their identity, there are also many that do not. If at a future time, this account becomes associated with their identity for a larger audience than they desire, they can make their whole account viewable only by approved followers2, delete the account, or delete some of the tweets. Of course, this information may remain elsewhere on the Internet for a short or long time. But in contrast, the Library of Congress archive will be much more enduring and likely outside of individual users’ control.3 While I think it is worth examining the strategies that people adopt to cope with inflexible or difficult to use privacy controls in software, I don’t intend to do that here.
Instead, I want to relate this discussion to my continued interest in how activity streams and other information consumption interfaces affect their users’ beliefs and behaviors through the availability heuristic. In response to some comments on his first post, Stutzman argues that people overestimate the degree to which content once public on the Internet is public forever:
So why is it that we all assume that the content we share publicly will be around forever? I think this is a classic case of selection on the dependent variable. When we Google ourselves, we are confronted with what’s there as opposed to what’s not there. The stuff that goes away gets forgotten, and we concentrate on things that we see or remember (like a persistent page about us that we don’t like). In reality, our online identities decay, decay being a stochastic process. The internet is actually quite bad at remembering.
This unconsidered “selection on the dependent variable” is one way of thinking about some cases of how the availability heuristic (and use of ease-of-retrievel information more generally). But I actually think the latter is more general and more useful for describing the psychological processes involved. For example, it highlights both that there are many occurrences or interventions can can influence which cases are available to mind and that even if people have thought about cases where their content disappeared at some point, this may not be easily retrieved when making particular privacy decisions or offering opinions on others’ actions.
Stutzman’s example is but one way that the combination of the availability heuristic and existing Internet services combine to affect privacy decisions. For example, consider how activity streams like Facebook News Feed influence how people perceive their audience. News Feed shows items drawn from an individual’s friends’ activities, and they often have some reciprocal access. However, the items in the activity stream are likely unrepresentative of this potential and likely audience. “Lurkers” — people who consume but do not produce — are not as available to mind, and prolific producers are too available to mind for how often they are in the actual audience for some new shared content. This can, for example, lead to making self-disclosures that are not appropriate for the actual audience.
- This might not be the case, see Michael Zimmer and this New York Times article. [↩]
- Why don’t people do this in the first place? Many may not be aware of the feature, but even if they are, there are reasons not to use it. For example, it makes any participation in topical conversations (e.g., around a hashtag) difficult or impossible. [↩]
- Or at least this control would have to be via Twitter, likely before archiving: “We asked them [Twitter] to deal with the users; the library doesn’t want to mediate that.” [↩]
“Discovering Supertaskers”: Challenges in identifying individual differences from behavior
Some new research from the University of Utah suggests that a small fraction of the population consists of “supertaskers” whose performance is not reduced by multitasking, such as when completing tasks on a mobile phone while driving.
“Supertaskers did a phenomenal job of performing several different tasks at once,” Watson says. “We’d all like to think we could do the same, but the odds are overwhelmingly against it.” (Wired News & Science News)
The researchers, Watson and Strayer, argue that they have good evidence for the existence of this individual variation. One can find many media reports of this “discovery” of “supertaskers” (e.g., Psychology Today). I do not think this conclusion is well justified.
First, let’s consider the methods used in this research. 100 college students each completed driving tasks and an auditory task on a mobile phone — separately and in combination — over a single 1.5 hour session. The auditory task is designed to measure differences in executive attention by requiring participants do hold past items in memory while completing math tasks. The researchers identified “supertaskers” as those participants who met the following “stringent” requirements: they were both (a) in the top 25% of participants in performance in the single-task portions and (b) and not different in their dual-task performance on at least three of the four measures by more than the standard error. Since two of the four measures are associated with each of the two tasks (driving: brake reaction time, following distance; mobile phone task: memory performance, math performance), this requires that ”supertaskers” do as well on both measures of either the driving or mobile phone task and one measure of the other task.
There may be many issues with the validity of the inference in this work. I want to focus on one in particular: the inference from the observation of differences between participants’ performance in a single 1.5 hour session to the conclusion that there are stable, “trait” differences among participants, such that some are “supertaskers”. This conclusion is simply not justified. To illustrate this, let’s consider how the methods of this study differ from those usually (and reasonably) used by psychologists to reach such conclusions.
Psychologists often study individual differences using the following approach. First, identify some plausible trait of individuals. Second, construct a questionnaire or other (perhaps behavioral) test that measures that trait. Third, demonstrate that this test has high reliability — that is, that the differences between people are much larger than the differences between the same person taking the test at different times. Fourth, then use this test to measure the trait and see if it predicts differences in some experiment. A key point here is that in order to conclude that the test measures a stable individual difference (i.e., a trait) researchers need to establish high test-retest reliability; otherwise, the test might just be measuring differences in temporary mood.
Returning to Watson and Strayer’s research, it is easy to see the problem: we have no idea whether the variation observed should be attributed to stable individual differences (i.e., being a “supertasker”) or to unstable differences. That is, if we brought those same “supertasker” participants back into the lab and they did another session, would they still exhibit the same lack of performance difference between the single- and dual-task conditions? This research gives us no reason that expect that they would.
Watson and Strayer do some additional analysis with the aim of ruling out their observations being a fluke. One might think this addresses my criticism, but it does not. They
performed a Monte Carlo simulation in which randomly selected single-dual task pairs of variables from the existing data set were obtained for each of the 4 dependent measures and then subjected to the same algorithm that was used to classify the supertaskers.
That is, they broke apart the single-task and dual-task data for each participant and created new simulated participants by randomly sampling pairs single- and dual-task data. They found that on this analysis there would be only 1/15th of the observed ”supertaskers”. This is a good analysis to do. However, this just demonstrates that being labeled a “supertasker” is likely caused by the single- and dual-task data being generated by the same person in the same session. This stills leaves it quite open (and more plausible to me) that participants’ were in varying states for the session and this explains their (temporary) “supertasking”. It also allows that this greater frequency of “supertaskers” is due to participants who do well in whatever task they are given first being more likely to do well in subsequent tasks.
My aim in this post is to suggest some challenges that this kind of approach has to face. Part of my interest in this is that I’m quite sympathetic to identifying stable, observed differences in behavior and then “working backwards” to characterizing the traits that explain these downstream differences. This exactly the approach that Maurits Kaptein and I are taking in our work on persuasion profiling: we observe how individuals respond to the use of different influence strategies and use this to (a) construct a “persuasion profile” for that individual and (b) characterize how much variation in the effects of these strategies there is in the population.
However, a critical step in this process is ruling out the alternative explanation that the observed differences are primarily due to differences in, e.g., mood, rather than stable individual differences. One way to do this is to observe the behavior in multiple sessions and multiple contexts. Another way to rule out this alternative explanation is if you observe a complex pattern of behavioral differences that previous work suggests could not be the result of temporary, unstable differences — or at least is more easily explained by previous theories about the relevant traits. That is, I’m enthusiastic about identifying stable, observed differences in behavior, but I don’t want to see researchers abandon the careful methods that have been used in the past to make the case for a new individual difference.
Watson, Strayer, and colleagues have apparently begun doing work that could be used to show the stability of the observed differences. The discussion section of their paper refers to some additional unpublished research in which they invited their “supertaskers” from this study and another study back into the lab and had them do some similar tasks measuring executive attention (but not driving) while in an fMRI machine. They report greater “coherence” in their performance in this second study and the previous study than control participants and better performance for “supertaskers” on dual-N-back tasks. But this is short of showing high test-retest reliability.
Since little is said about this work, I hesitate to conclude anything from it or criticize it. I’ve contacted the authors with the hope of learning more. My current sense is that Watson and Strayer’s entire case for “supertaskers” hinges on research of this kind.
References
Watson, J. M., & Strayer, D. L. (2010). Supertaskers: Profiles in Extraordinary Multi-tasking Ability. Psychonomic Bulletin and Review. Forthcoming. Retrieved from http://www.psych.utah.edu/lab/appliedcognition/publications/supertaskers.pdf
Persuasion profiling and genres: Fogg in 2006
Maurits Kaptein and I have recently been thinking a lot about persuasion profiling — estimating and adapting to individual differences in responses to influence strategies based on past behavior and other information. With help from students, we’ve been running experiments and building statistical models that implement persuasion profiling.
My thinking on persuasion profiling is very much in BJ Fogg’s footsteps, since he has been talking about persuasion profiling in courses, lab meetings, and personal discussions since 2004 or earlier.
Just yesterday, I came across this transcript of BJ’s presentation for an FTC hearing in 2006. I was struck at how much it anticipates some of what Maurits and I have written recently (more on this later). I’m sure I watched the draft video of the presentation back then and it’s influenced me, even if I forgot some of the details.
Here is the relevant excerpt from BJ’s comments for the FTC:
Persuasion profiling means that each one of us has a different set of persuasion strategies that affect us. Just like we like different types of food or are vulnerable to giving in to different types of food on a diet, we are vulnerable to different types of persuasion strategies.
On the food example, I love old-fashioned popcorn, and if I go to a party and somebody has old-fashioned popcorn, I will probably break down and eat it. On the persuasion side of things, I know I’m vulnerable to trying new things, to challenges and to anything that gets measured. If that’s proposed to me, I’m going to be vulnerable and I’m going to give it a shot.
Whenever we go to a Web site and use an interactive system, it is likely they will be capturing what persuasion strategies work on us and will be using those when we use the service again. The mapping out of what makes me tick, what motivates me can also be bought or sold, just like a credit report.
So imagine I’m going in to buy a new car and the person selling me the car downloads my credit report but also buys my persuasion profile. I may or may not know about this. Imagine if persuasion profiles are available on political campaigns so that when I visit a Web site, the system knows it is B.J. Fogg, and it changes [its] approach based on my vulnerabilities when it comes to persuasion.
Persuasive technology will touch our lives anywhere that we access digital products or services, in the car, in our living room, on the Web, through our mobile phones and so on. Persuasive technology will be all around us, and unlike other media types, where you have 30-second commercial or a magazine ad, you have genres you can understand, when it comes to computer-based persuasion, it is so flexible that it won’t have genre boundaries. It will come to us in the ordinary course of our lives, as we are working on a Web site, as we are editing a document, as we are driving a car. There won’t be clear markers about when you are being persuaded and when you are not.
This last paragraph is about the “genrelessness” of many persuasive technologies. This isn’t directly on the topic of persuasion profiling, but I see it as critically relevant. Persuasion profiling is likely to be most effective when invisible and undisclosed to users. From this and the lack of genre-based flags for persuasive technology it follows that we will frequently be “persuasion profiled” without knowing it.
Keyword searching papers citing a highly-cited paper with Google Scholar
[Update: Google Scholar now directly supports this feature, check the box right below the search box after clicking “Cited by…”.]
In finding relevant research, once one has found something interesting, it can be really useful to do “reverse citation” searches.
Google Scholar is often my first stop when finding research literature (and for general search), and it has this feature — just click “Cited by 394”. But it is not very useful when your starting point is highly cited. What I often want to do is to do a keyword search of the papers that cite my highly-cited starting point.
While there is no GUI for this search within these results in Google Scholar, you can actually do it by hacking the URL. Just add the keyword query to the URL.
This is the URL one gets for all resources Google has as citing Allport’s “Attitudes” (1935):
http://scholar.google.com/scholar?cites=9150707851480450787&hl=en
And this URL searches within those for “indispensable concept”:
http://scholar.google.com/scholar?hl=en&cites=9150707851480450787&q=indispensable+concept
In this particular case, this gives us many examples of authors citing Allport’s comment that the attitude is the most distinctive and indispensable concept in social psychology. This example highlights that this can even just help get more useful “snippets” in the search results, even if it doesn’t narrow down the results much.
I find this useful in many cases. Maybe you will also.
Apple’s “trademarked” chat bubbles: source equivocality in mobile apps and services
TechCrunch and others have been joking about Apple’s rejection of an app because it uses shiny chat bubbles, which the Apple representative claimed were trademarked:
Chess Wars was being rejected after the six week wait [because] the bubbles in its chat rooms are too shiny, and Apple has trademarked that bubbly design. […] The representative said Stump needed to make the bubbles “less shiny” and also helpfully suggested that he make the bubbles square, just to be sure.
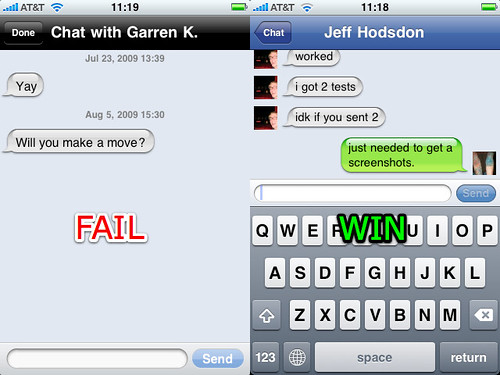
One thing that is quite striking in this situation is that it is at odds with Apple’s long history of strongly encouraging third-party developers to follow many UI guidelines — guidelines that when followed make third-party apps blend in like they’re native.1
It’s important to not read too much into this (especially since we don’t know what Apple’s more considered policy on this will end up being), but it is interesting to think about how responsibility gets spread around among mobile applications, services, and devices — and how this may be different than existing models on the desktop.My sense is that experienced desktop computer users understand at least the most important ways sources of their good and bad experiences are distinguished. For example, “locomotion” is a central metaphor in using the Web, as opposed to the conversation and manipulation metaphors of the command line / natural language interfaces and WIMP: we “go to” a site (see this interview with Terry Winograd, full .mov here). The locomotion metaphor helps people distinguish what my computer is contributing and what some distant, third-party “site” is contributing.
This is complex even on the Web, but many of these genre rules are currently being all mixed up. Google has Gmail running in your browser but on your computer. Cameraphones are recognizing objects you point them at — some by analyzing the image on the device and some by sending the device to a server to be analyzed.
This issue is sometimes identified by academics as one of source orientation and source equivocality. Though there has been some great research in this area, there is a lot we don’t know and the field is in flux: people’s beliefs about systems are changing and the important technologies and genres are still emerging.
If there’s one important place to start thinking about the craziness of the current situation of ubiquitous source equivocality is “Personalization of mass media and the growth of pseudo-community” (1987) by James Beniger that predates much of the tech at issue.
- I was led to think this by a commenter on TechCrunch, Dan Grossman, pointing out this long history. [↩]