Do what the virtuous person would do?
In the film The Descendents, George Clooney’s character Matt King wrestles — sometimes comically — with new and old choices involving his family and Hawaii. In one case, King decides he wants to meet a rival, both just to meet him and to give him some news; that is, he (at least explicitly) has generally good reason to meet him. Perhaps he even ought to meet him. When he actually does meet him, he cannot just do these things, he also argues with his rival, etc. King’s unplanned behaviors end up causing his rival considerable trouble.1
This struck me as related to some challenges in formulating what one should do — that is, in the “practical reasoning” side of ethics.
One way of getting practical advice out of virtue ethics is to say that one should do what the virtuous person would do in this situation. On its face, this seems right. But there are also some apparent counterexamples. Consider a short-tempered tennis player who has just lost a match.2 In this situation, the virtuous person would walk over to his opponent, shake his hand, and say something like “Good match.” But if this player does that, he is likely to become enraged and even assault his victorious opponent. So it seems better for him to walk off the court without attempting any of this — even though this is clearly rude.
The simple advice to do what the virtuous person would do in the present situation is, then, either not right or not so simple. It might be right, but not so simple to implement, if part of “the present situation” is one’s own psychological weaknesses. Aspects of the agent’s psychology — including character flaws — seem to license bad behavior and to remove reasons for taking the “best” actions.
King and other characters in The Descendents face this problem, both in the example above and at some other points in the movie. He begins a course of action (at least in part) because this is what the virtuous person would do. But then he is unable to really follow through because he lacks the necessary virtues.3 We might take this as a reminder of the ethical value to being humble — to account for our faults — when reasoning about what we ought to do.4 It is also a reminder of how frustrating this can be, especially when one can imagine (and might actually be able to) following through on doing what the virtuous person would do.
One way to cope with these weaknesses is to leverage other aspects of one’s situation. We can make public commitments to do the virtuous thing. We can change our environment, sometimes by binding our future selves, like Ulysses, from acting on our vices once we’ve begun our (hopefully) virtuous course of action. Perhaps new mobile technologies will be a substantial help here — helping us intervene in our own lives in this way.
- Perhaps deserved trouble. But this certainly didn’t play a stated role in the reasoning justifying King’s decision to meet him. [↩]
- This example is first used by Gary Watson (“Free Agency”, 1975) and put to this use by Michael Smith in his “Internalism” (1995). Smith introduces it as a clear problem for the “example” model of how what a virtuous person would do matters for what we should each do. [↩]
- Another reading of some of these events in The Descendents is that these characters actually want to do the “bad behaviors”, and they (perhaps unconciously) use their good intentions to justify the course of action that leads to the bad behavior. [↩]
- Of course, the other side of such humility is being short on self-efficacy. [↩]
Ethical persuasion profiling?
Persuasion profiling — estimating the effects of available influence strategies on an individual and adaptively selecting the strategies to use based on these estimates — sounds a bit scary. For many, ‘persuasion’ is a dirty word and ‘profiling’ generally doesn’t have positive connotations; together they are even worse! So why do we use this label?
In fact, Maurits Kaptein and I use this term, coined by BJ Fogg, precisely because it sounds scary. We see the potential for quite negative consequences of persuasion profiling, so we try to alert our readers to this.1
On the other hand, we also think that, not only is persuasion profiling sometimes beneficial, but there are cases where choosing not to adapt to individual differences in this way might itself be unethical.2 If a company marketing a health intervention knows that there is substantial variety in how people respond to the strategies used in the intervention — such that while the intervention has positive effects on average, it has negative effects for some — it seems like they have two ethical options.
First, they can be honest about this in their marketing, reminding consumers that it doesn’t work for everyone or even trying to market it to people it is more likely to work for. Or they could make this interactive intervention adapt to individuals — by persuasion profiling.
Actually for the first option to really work, the company needs to at least model how these responses vary by observable and marketable-to characteristics (e.g., demographics). And it may be that this won’t be enough if there is too much heterogeneity: even within some demographic buckets, the intervention may have negative effects for a good number of would-be users. On the other hand, by implementing persuasion profiling, the intervention will help more people, and the company will be able to market it more widely — and more ethically.
A simplified example that is somewhat compelling to me at least, but certainly not airtight. In another post, I’ll describe how somewhat foreseeable, but unintended, consequences should also give one pause.
- You might say we tried to build in a warning for anyone discussing or promoting this work. [↩]
- We argue this in the paper we presented at Persuasive Technology 2010. The text below reprises some of what we said about our “Example 4” in that paper.
Kaptein, M. & Eckles, D. (2010). Selecting effective means to any end: Futures and ethics of persuasion profiling. Proceedings of Persuasive Technology 2010, Lecture Notes in Computer Science. Springer. [↩]
“Discovering Supertaskers”: Challenges in identifying individual differences from behavior
Some new research from the University of Utah suggests that a small fraction of the population consists of “supertaskers” whose performance is not reduced by multitasking, such as when completing tasks on a mobile phone while driving.
“Supertaskers did a phenomenal job of performing several different tasks at once,” Watson says. “We’d all like to think we could do the same, but the odds are overwhelmingly against it.” (Wired News & Science News)
The researchers, Watson and Strayer, argue that they have good evidence for the existence of this individual variation. One can find many media reports of this “discovery” of “supertaskers” (e.g., Psychology Today). I do not think this conclusion is well justified.
First, let’s consider the methods used in this research. 100 college students each completed driving tasks and an auditory task on a mobile phone — separately and in combination — over a single 1.5 hour session. The auditory task is designed to measure differences in executive attention by requiring participants do hold past items in memory while completing math tasks. The researchers identified “supertaskers” as those participants who met the following “stringent” requirements: they were both (a) in the top 25% of participants in performance in the single-task portions and (b) and not different in their dual-task performance on at least three of the four measures by more than the standard error. Since two of the four measures are associated with each of the two tasks (driving: brake reaction time, following distance; mobile phone task: memory performance, math performance), this requires that ”supertaskers” do as well on both measures of either the driving or mobile phone task and one measure of the other task.
There may be many issues with the validity of the inference in this work. I want to focus on one in particular: the inference from the observation of differences between participants’ performance in a single 1.5 hour session to the conclusion that there are stable, “trait” differences among participants, such that some are “supertaskers”. This conclusion is simply not justified. To illustrate this, let’s consider how the methods of this study differ from those usually (and reasonably) used by psychologists to reach such conclusions.
Psychologists often study individual differences using the following approach. First, identify some plausible trait of individuals. Second, construct a questionnaire or other (perhaps behavioral) test that measures that trait. Third, demonstrate that this test has high reliability — that is, that the differences between people are much larger than the differences between the same person taking the test at different times. Fourth, then use this test to measure the trait and see if it predicts differences in some experiment. A key point here is that in order to conclude that the test measures a stable individual difference (i.e., a trait) researchers need to establish high test-retest reliability; otherwise, the test might just be measuring differences in temporary mood.
Returning to Watson and Strayer’s research, it is easy to see the problem: we have no idea whether the variation observed should be attributed to stable individual differences (i.e., being a “supertasker”) or to unstable differences. That is, if we brought those same “supertasker” participants back into the lab and they did another session, would they still exhibit the same lack of performance difference between the single- and dual-task conditions? This research gives us no reason that expect that they would.
Watson and Strayer do some additional analysis with the aim of ruling out their observations being a fluke. One might think this addresses my criticism, but it does not. They
performed a Monte Carlo simulation in which randomly selected single-dual task pairs of variables from the existing data set were obtained for each of the 4 dependent measures and then subjected to the same algorithm that was used to classify the supertaskers.
That is, they broke apart the single-task and dual-task data for each participant and created new simulated participants by randomly sampling pairs single- and dual-task data. They found that on this analysis there would be only 1/15th of the observed ”supertaskers”. This is a good analysis to do. However, this just demonstrates that being labeled a “supertasker” is likely caused by the single- and dual-task data being generated by the same person in the same session. This stills leaves it quite open (and more plausible to me) that participants’ were in varying states for the session and this explains their (temporary) “supertasking”. It also allows that this greater frequency of “supertaskers” is due to participants who do well in whatever task they are given first being more likely to do well in subsequent tasks.
My aim in this post is to suggest some challenges that this kind of approach has to face. Part of my interest in this is that I’m quite sympathetic to identifying stable, observed differences in behavior and then “working backwards” to characterizing the traits that explain these downstream differences. This exactly the approach that Maurits Kaptein and I are taking in our work on persuasion profiling: we observe how individuals respond to the use of different influence strategies and use this to (a) construct a “persuasion profile” for that individual and (b) characterize how much variation in the effects of these strategies there is in the population.
However, a critical step in this process is ruling out the alternative explanation that the observed differences are primarily due to differences in, e.g., mood, rather than stable individual differences. One way to do this is to observe the behavior in multiple sessions and multiple contexts. Another way to rule out this alternative explanation is if you observe a complex pattern of behavioral differences that previous work suggests could not be the result of temporary, unstable differences — or at least is more easily explained by previous theories about the relevant traits. That is, I’m enthusiastic about identifying stable, observed differences in behavior, but I don’t want to see researchers abandon the careful methods that have been used in the past to make the case for a new individual difference.
Watson, Strayer, and colleagues have apparently begun doing work that could be used to show the stability of the observed differences. The discussion section of their paper refers to some additional unpublished research in which they invited their “supertaskers” from this study and another study back into the lab and had them do some similar tasks measuring executive attention (but not driving) while in an fMRI machine. They report greater “coherence” in their performance in this second study and the previous study than control participants and better performance for “supertaskers” on dual-N-back tasks. But this is short of showing high test-retest reliability.
Since little is said about this work, I hesitate to conclude anything from it or criticize it. I’ve contacted the authors with the hope of learning more. My current sense is that Watson and Strayer’s entire case for “supertaskers” hinges on research of this kind.
References
Watson, J. M., & Strayer, D. L. (2010). Supertaskers: Profiles in Extraordinary Multi-tasking Ability. Psychonomic Bulletin and Review. Forthcoming. Retrieved from http://www.psych.utah.edu/lab/appliedcognition/publications/supertaskers.pdf
Apple’s “trademarked” chat bubbles: source equivocality in mobile apps and services
TechCrunch and others have been joking about Apple’s rejection of an app because it uses shiny chat bubbles, which the Apple representative claimed were trademarked:
Chess Wars was being rejected after the six week wait [because] the bubbles in its chat rooms are too shiny, and Apple has trademarked that bubbly design. […] The representative said Stump needed to make the bubbles “less shiny” and also helpfully suggested that he make the bubbles square, just to be sure.
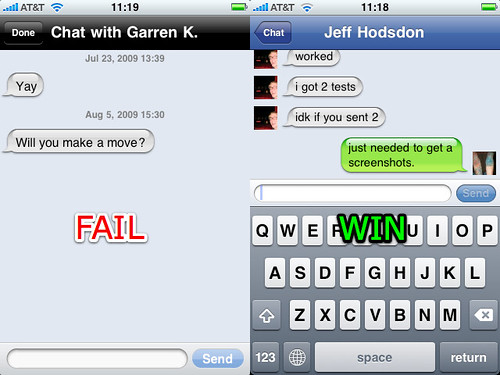
One thing that is quite striking in this situation is that it is at odds with Apple’s long history of strongly encouraging third-party developers to follow many UI guidelines — guidelines that when followed make third-party apps blend in like they’re native.1
It’s important to not read too much into this (especially since we don’t know what Apple’s more considered policy on this will end up being), but it is interesting to think about how responsibility gets spread around among mobile applications, services, and devices — and how this may be different than existing models on the desktop.My sense is that experienced desktop computer users understand at least the most important ways sources of their good and bad experiences are distinguished. For example, “locomotion” is a central metaphor in using the Web, as opposed to the conversation and manipulation metaphors of the command line / natural language interfaces and WIMP: we “go to” a site (see this interview with Terry Winograd, full .mov here). The locomotion metaphor helps people distinguish what my computer is contributing and what some distant, third-party “site” is contributing.
This is complex even on the Web, but many of these genre rules are currently being all mixed up. Google has Gmail running in your browser but on your computer. Cameraphones are recognizing objects you point them at — some by analyzing the image on the device and some by sending the device to a server to be analyzed.
This issue is sometimes identified by academics as one of source orientation and source equivocality. Though there has been some great research in this area, there is a lot we don’t know and the field is in flux: people’s beliefs about systems are changing and the important technologies and genres are still emerging.
If there’s one important place to start thinking about the craziness of the current situation of ubiquitous source equivocality is “Personalization of mass media and the growth of pseudo-community” (1987) by James Beniger that predates much of the tech at issue.
- I was led to think this by a commenter on TechCrunch, Dan Grossman, pointing out this long history. [↩]
Etching by Da Vinci? Representing legend, culture, and language

- A photo I took in Piazza della Signoria of an etching, reportedly a self-portrait of Leonardo da Vinci that he etched behind his back on a dare onto the side of the Palazzo Vecchio.
Is this etching a self-portrait by Leonardo da Vinci created hundreds of years ago? That’s what I was told by a Californian friend who had “gone native” in Florence. Another matter: is this, in fact, a commonly believed and shared legend, and what other variations are there on it?
I shared the story with some fellow visitors in Florence on a lunch-time return to the piazza. Ed Chi tried to verify the rumor using a Web search, but with no success. At least in English, there didn’t seem to be much on this in the Web. (See my photo and comments on Flickr.)
I posted the photo on Flickr. I asked questions on LinkedIn and Yahoo! Answers, with no success. I also asked for help from workers on Mechanical Turk. Here’s part of how I asked for help:
There is a portrait etched in stone on the wall of Palazzo Vecchio in Piazza della Signoria in Florence (Firenza), Italy. It is close behind the copy of the David there. I have heard that there is a legend that this is a self-portrait by Leonardo da Vinci. I am looking for any information about this legend, alternate versions of the legend, or information about the real source of the portrait.
What results have been offered seem to suggest that this legend exists — though perhaps it is “actually” (at least as captured online, since perhaps the Leonardo theorists aren’t as active digital content creators) about Michelangelo:
- Palazzo Vecchio in Italian Wikipedia
- Florentine Legends: Fact or Fiction (in Italian)
- Curiosities in Florence
The best way of finding out seemed to actually be my Flickr photo itself, since that’s where Daniel Witting provided the first two links above — however, this was a few months after the photo was first posted to Flickr. Turkers provided a couple useful links also (“Curiosities” above) on a shorter schedule and with a higher price. (I should have also tried uClue — where many former Google Answers researchers now work. This was recommended by Max Harper, who has studied Q&A sites in detail.)
–
Question and answer services along the lines of Yahoo! Answers rose to global (and U.S.) significance only after success in Korea, where Naver Knowledge iN pioneered the use of an online community to power a Q&A site. A major motivation Korea was the limited amount of Korean content online. With Naver’s offering, Korea’s Internet saavy, English population made information newly available in Korean (and did plenty of other interesting work).
This is as significant a motivation for Q&A sites by English-speaking folks in the U.S., but the present case is an exception.
Some of the questions that made this case interesting to me:
- What culturally-shared beliefs get manifest online? During this whole process, I and others wondered whether perhaps this local legend was only shared orally. It seems that it is represented online after all — at least the Michelangelo variant, but it could have been otherwise.
- How does the pair of languages a task requires knowledge of determine the processes, structres, and communities that are optimal for completing the task? For example, it seems quite important whether the target or source language has many more speakers than the other. (One could think about this simplistically in terms of conditional probabilities of skills with language A given skill with language B and vice verse.)